Introduction to Operating Systems
컴퓨터 분야의 학문은 아래의 두 가지 분야로 나뉘지만 복잡도(complexity)가 매우 높은 문제를 다루고 있어서 방법론적인 차원에서는 크게 다르지 않다.
- 컴퓨터 자체를 효율적으로 운영하기 위한 학문
- 복잡한 문제를 컴퓨터를 활용하여 효율적으로 풀 수 있는 방법을 제공하기 위한 방법
컴퓨터가 일을 처리하는 방식은 정확한 처리 방식을 알고리즘이라는 형식을 통해 기술해 주어야 하고, 작업 내용의 복잡도가 매우 높아서 사람이 하는 것처럼 눈썰미나 직감으로 처리할 수 없다. 특히 데이터의 수가 많아질수록 효율적으로 작업을 수행할 수 있도록 하는 체계적인 방법이 필요하다. 그 체계적인 방법 중 하나가 컴퓨터 하드웨어와 스프트웨어를 총체적으로 관리하는 핵심 소프트웨어인 운영체제이다.
컴퓨터 및 정보 기술의 역사
1. 이론적 기원
수학과 논리학에서 컴퓨터의 이론적 기원을 찾아볼 수 있다. 어떠한 문제를 수학적인 모델로 표현하는 방법을 개발하고, 그 문제를 풀기 위한 알고리즘을 기술할 수 있는 컴퓨터에 대한 추상적인 모델을 설계했다. (e.g. 튜링 머신)
2. 기계식 컴퓨터
컴퓨터는 계산을 빠르게 하기 위해 개발되었다. 19세기 해석기관(analytic engine)는 프로그램이 가능한 최초의 기계식 컴퓨터이다. 베비지가 설계한 이 컴퓨터는 현대의 컴퓨터에서 발견되는 네 가지 기본 구성 요소인 입력 장치, 출력 장치, 처리 장치, 저장 장치를 포함하고 있다.
3. 전자식 컴퓨터
20세기 초에 전자식 계산기가 등장하고, 이는 전자 장치에 의해 동작하는 본격적인 의미의 컴퓨터이다. ABC, Mark1, ENIAC 등이 만들어졌다. 특히 ENIAC은 최초의 현대적 컴퓨터로 인식된다. 이를 기점으로 컴퓨터 역사의 경계를 나누기도 한다.
4. 근대적 컴퓨터
근대로 넘어오면 변화가 매우 빨라져서 시대적 분류가 쉽지 않지만 1940년대 중빈부터 하드웨어 기술 발전을 토대로 대체로 1~4세대로 분류한다.
- 1세대 컴퓨터: 1940년대 후반 시작된 진공관 기반 컴퓨터
- 2세대 컴퓨터: 1950년대 후반 시작된 트랜지스터 기반 컴퓨터
- 3세대 컴퓨터: 1960년대 후반 시작된 직접회로 기반 컴퓨터
- 4세대 컴퓨터: 1970년대 중반 시작된 LSI(Large Scale Integration), VLSI(Very Large Scale Integration) 기반 마이크로 컴퓨터
2세대부터 소프트웨어의 발전이 크게 이루어지고, 컴퓨터의 사용이 확산되면서 프로그래밍의 필요성도 크게 증가한다. 그에 따라 기계어로 프로그래밍을 하는 불편함 때문에 사람이 프로그래밍 하기 수월한 언어의 필요성이 대두되었고, 어셈블리 언어가 등장한다. 그외 고급 언어인 포트란, 리습(Lisp) 언어, 코볼(Cobol) 등이 개발된다. 1960년대 이후에는 설계의 방법론이라 할 수 있는 소프트웨어 공학이 부각되면서 구조적 프로그래밍 기법이 부각된다. 또한 알골 60(Algol 60)이라는 언어가 등장했고, 운영 체제가 개발되기 시작한다. 그 이유는 초기에는 컴퓨터 외부에서 미리 예약해서 한꺼번에 처리하는 일괄 처리 방식(batch processing)을 사용했는데, 그것이 비효율적이기 때문에 컴퓨터 자체가 이런한 것을 자동적으로 처리해 주도록 하는 방식을 생각하여 운영 체제가 생겨났다. 컴퓨터의 응용 분야로는 경영 자동화가 부각되면서 데이터베이스 관리 시스템(DBMS: DataBase Management System)도 등장한다. 1960년대 중반부터는 특히 반도체 기술의 빠른 발전으로 인해 컴퓨터 하드웨어에 큰 변화가 있었고, 1970년대에 들어서면서 하드웨어와 소프트웨어의 설계 방법론 측면이 크게 부각된다. 그 이유는 하드웨어가 반도체 기술의 발전과 그로 인한 직접 회로(IC)의 발전으로 상당한 성능 향상이 있었지만 소프트웨어쪽은 그다지 만족한 말한 발전을 이루지 못했기 때문이다. 하지만 이런 하드웨어의 고도화로 개인용 컴퓨터가 등장하고, 컴퓨터 네트워크에 대한 발전의 기초를 마련하게 된다. 이 시기에는 C언어가 개발되었다. 또한 마이크로프로세서가 직접회로를 더욱 고도화한 초고밀도 직접회로(VLSI)기술로 제작되면서 4세대 컴퓨터 시대를 열게 된다. 이 마이크로프로세서의 보급이 개인용 컴퓨터 혁명을 야기하여 1960년대 후반부터는 애플, 코모도, 탠디 등의 회사가 개인용 컴퓨터의 생산을 시작한다. 1980년대에 소프트웨어 방법론이 많이 등장하게 되고, 객체 지향 언어가 성공한다. 1990년대 초반부터는 컴퓨터가 사회 전반으로 뿌리내리게 되면서 인텔 펜티엄 프로세서, 윈도우 95, 월드 와이드 웹, 자바 등이 등장한다.
오늘날 현대의 컴퓨터는 규모에 따라 여러 가지로 나뉠 수 있는데, 보통 임의의 목적으로 사용될 수 있는 것을 범용 컴퓨터라고 부르고, 특수 목적을 위해 각종 장치의 제어용으로 내장되는 컴퓨터를 임베디드 컴퓨터라고 부른다.
슈퍼 컴퓨터, 메인 프레임 컴퓨터
마이크로프로세서 등장 이전의 컴퓨터는 대부분 커다란 크기의 메인 프레임 컴퓨터였다.
- 메인 프레임 컴퓨터: 일반적으로 터미널을 통해 접속한다. 시분항 방식(컴퓨터 처리 능력을 짧은 시간 단위로 구분하여 여러 사용자에게 조금씩 분할해서 서비스)을 사용한다.
- 슈퍼 컴퓨터: 메인 프레임 컴퓨터로 처리 능력이 부족한 응용 분야에 쓰인다. (e.g. 기상 예측, 통신망 설계, 석유 탐사 등) 복잡한 문제를 다루기 때문에 처리 능력이 메인 프레임 컴퓨터보다 뛰어나야 하기 때문에 슈퍼 컴퓨터 또는 고성능 컴퓨터라고도 부른다.
개인용 컴퓨터
메인 프레임 컴퓨터를 사용하기에는 규모가 작은 연구실이나 사무실에서 쓰는 워크스테이션의 개념이 등장한다. 이는 10인 이내의 구성원이 공동으로 사용하기에 적절한 컴퓨터를 의미한다. 최근에는 개인용 컴퓨터의 성능이 좋아져서 워크스테이션과 개인용 컴퓨터의 격차가 많이 사라졌다.
휴대용 컴퓨터
데스크탑 컴퓨터와 달리 휴대가 가능한 컴퓨터를 휴대용 컴퓨터라 하는데, 랩탑 컴퓨터가 있다. 랩탑보다 더 작은 사이즈의 스마트 폰도 있다.
임베디드 컴퓨터
특수한 목적을 가지고 제작되는 컴퓨터로 각종 기기에 포함되어 그 기능을 향상시키거나 연산, 처리, 전달 등의 업무를 담당한다. 칩이 내부에 구워져 있어서 범용 컴퓨터와 같은 일반적인 방법으로 프로그램을 올릴 수 없다. 용도의 특수성으로 인해서 한번 기록된 프로그램이 수정될 일이 거의 없기 때문이다.
운영 체제 개요
운영체제: 컴퓨터 하드웨어 바로 윗단에 설치되는 소프트웨어. 사용자 및 다른 모든 소프트웨어와 하드웨어를 연결하는 소프트웨어 계층
운영 체제가 없으면 컴퓨터는 고철 덩어리에 불가하다. 하드웨어가 운영 체제와 한 몸이 되어야만 사용자에게 쓰일 수 있는 진정한 컴퓨터 시스템이 된다. 사용자가 하드웨어 자체를 다루는 것이 쉽지 않으므로 하드웨어 위에 운영체제를 탑재하여 전원을 켰을 때 사용자가 손쉽게 사용할 수 있는 상태가 되도록 하는 것이다. 컴퓨터의 전원을 켜면 운영 체제도 켜지는 셈이다.
운영 체제의 기능
핵심 기능: 컴퓨터 시스템 내의 자원을 효율적으로 관리하여 가장 좋은 성능을 내도록 한다.
- 자원의 효율적 관리가 매우 중요하기 때문에 자원 관리자(resource manager)라 부르기도 한다.
- 자원: CPU, 메모리, 하드 디스크, 프로세스, 파일, 메시지 등 하드웨어와 소프트웨어 자원을 통칭한다.
- 단, 효율성 추구로 인해 일부가 지나치게 희생되지 않도록 하는
형평성의 문제도 고려해야 한다.
- (사용자 -> 프로그램 -> 추상화된 컴퓨터(Abstract Machine) ->
운영체제(에 의한 자원공유) -> 물리적인 컴퓨터 -> 결과(Result))
- 컴퓨터 시스템을 편리하게 사용할 수 있는 환경 제공
- 운영 체제가 동시 사용자 및 프로그램들에게 각각 독자적으로 컴퓨터를 사용하는 것과 같은 환상을 제공한다.
- 하드웨어를 직접 다루는 복잡한 부분을 운영 체제가 대행하고, 사용자 및 프로그램은 이에 대해 자세한 내용은 알지 못해도 프로그램을 계속 수행할 수 있다. (사용자 -> 프로그램 -> 추상화된 컴퓨터(Abstract Machine) -> 물리적인 컴퓨터 -> 결과(Result))
- 사용자와 운영체제 자신을 보호
운영 체제의 분류
1. 동시 작업을 진행하는 지 여부에 따라 분류한다.
- 단일 작업용 운영 체제: 한 번에 하나의 프로그램만 수행시킨다.
- 다중 작업: 동시에 두 개 이상의 프로그램을 처리할 수 있다.
다중 작업용 운영 체제의 개념은 잘 구분해서 정리해야 한다. 운영 체제가 다중 작업을 처리할 때 여러 프로그램이 CPU와 메모리를 공유하는 데, 일반적으로 컴퓨터에는 CPU가 하나 밖에 없다. 따라서 다중 작업용 운영 체제라도 CPU에서는 매 순간 하나의 프로그램만 수행된다.
- 시분할 시스템(time sharing system): CPU에서 수 밀리 세컨드(ms)이내에 여러 프로그램들이 번갈아가면서 수행된다. 따라서 사용자는 여러 프로그램이 동시에 수행되는 것처럼 느끼게 된다.
- 다중 프로그래밍 시스템(multi-programming system): 메모리 공간을 분할해 여러 프로그램들을 동시에 메모리에 올려놓고 처리한다. 대화형 시스템(interactive system)이라고도 부른다.
다중 작업, 시분할, 다중 프로그래밍은 모두 여러 프로그램이 하나의 컴퓨터에서 동시에 수행된다. 요즘의 운영체제는 대게 이러한 방식이다.
- 다중처리기 시스템(multi-processor system): 하나의 컴퓨터 안에 CPU가 여러 개 설치된 경우를 말한다.
2. 다중 사용자의 동시 지원 여부 (사용자의 수에 따른 분류)
- 단일 사용자용 운영 체제:
한 번에 한 명의 사용자만이 사용하도록 허용한다. e.g. MS_DOS, MS windows
- 다중 사용자용 운영 체제: 여러 사용자가 동시에 접속해 사용할 수 있게 한다. e.g. UNIX, NT server
3. 작업 처리 방식에 따른 분류
- 일괄 처리 방식(batch processing): 작업 요청의 일정량을
모아서 한꺼번에 처리한다. e.g. 펀치카드
- 시분할 방식(time sharing): 여러 작업을 수행할 때 컴퓨터의 처리 능력을 일정한 시간 단위로 분할하여 사용한다. e.g. UNIX
- 실시간 운영 체제(real time): 정해진 시간 안에 어떠한 일이 반드시 종료됨이 보장되어야 한다. e.g. 원자로, 공장 제어 시스템, 미사일 제어 시스템 등
운영 체제의 자원 관리 기능
운영 체제의 가장 핵심적인 기능은 자원을 효율적으로 관리. 자원은 CPU, 메모리 등을 비롯한 주변 장치 및 입출력 장치 등의 하드웨어 자원과 소프트웨어 자원으로 나뉜다.
하드웨어 자원 관리
CPU 스케줄링: 어떤 프로그램에게 CPU를 줄 것인가? CPU는 하나이기 때문에 매 시점 어떤 프로세스가 CPU를 할당해 작업을 처리할지 결정해야 한다.
선입 선출 기법: 먼저 CPU를 사용하기 위해 도착한 프로세스를 먼저 처리해준다. e.g. 줄서기라운드 로빈 기법: CPU를 한 번 할당받아 사용할 수 있는 시간을 일정한 고정된 시간으로 제한한다. 긴 작업을 요하는 프로세스가 CPU를 할당 받더라도 정해진 시간이 지나면 CPU를 내어놓아야 한다. 선입 선출 기법이 장시간 처리가 필요한 프로세스가 처리 될 동안 다른 프로세스들은 장시간 처리가 끝날때까지 기다려야 해서 전체 시스템상의 비효율이 발생하기 때문에 이를 보완하기 위한 방법으로 고안되었다.우선 순위 스케줄링: 수행 대기중인 프로세스들에게 우선순위를 부여하여 우선순위가 높은 프로세스에게 CPU를 먼저 할당한다.
파일 관리: 디스크에 파일을 어떻게 보관할 것인가? CPU, 메모리는 전원이 꺼지면 처리중이던 정보가 모두 꺼지므로 전원이 꺼져도 기억이 필요한 부분은 보조 기억 장치에 파일 형태로 저장한다. 이 파일들이 저장되는 방식 및 접근 권한 등을 OS가 관리해주어야 한다.입출력 관리: 각기 다른 입출력 장치와 컴퓨터 간에 어떻게 정보를 주고 받을 것인가? 키보드, 모니터, 하드 디스크 등
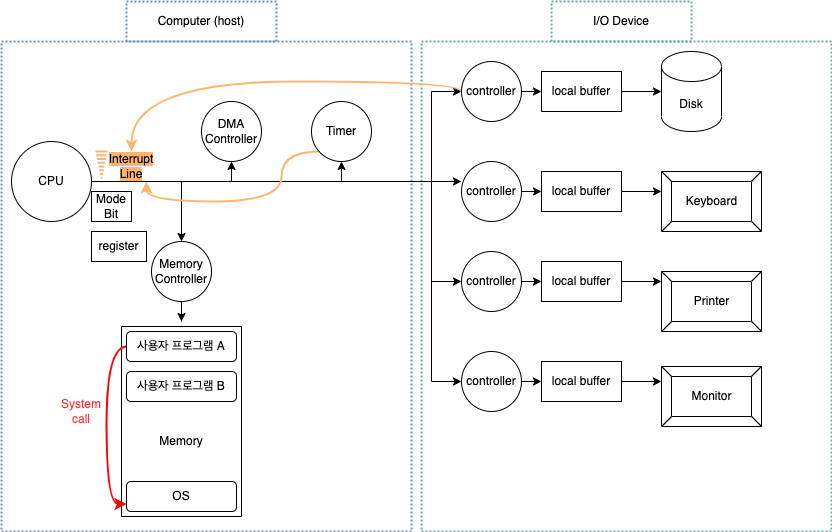
인터럽트: 주변 장치들이 CPU의 서비스가 필요한 경우 신호를 발생시켜 서비스를 요청하는데 이 신호를 인터럽트라고 한다. 그러면 CPU는 하던 작업을 멈추고 인터럽트가 요청한 서비스를 수행한다.컨트롤러: 주변 장치들이 각 장치마다 해당 장치에서 일어나는 업무에 대한 관리를 위한 일종의 작은 CPU를 가지고 있는데, 이를 컨트롤러라고 한다. 해당 장치에 대한 업무를 처리하고, 메인 CPU에 인터럽트를 발생시켜 보고하는 역할을 한다.
메모리 관리: 한정된 메모리를 어떻게 나누어 사용할 것인가? 메모리의 어느 부분이 어떤 프로그램에 의해 사용되고 있는지를 주소(address)를 통해 관리하고, 메모리가 필요할 때 할당하고, 그렇지 않을 때 회수한다.
고정 분할 방식: 물리적 메모리를 몇 개의 영구적인 분할로 나눈다. 동시에 메모리에 적재되는 최대 프로그램의 수가 분할 개수로 한정되어 융통성이 없다는 단점이 있고, 분할의 크기보다 큰 프로그램은 적재가 불가하다.
내부 조각: 분할의 크기보다 작은 프로그램이 적재되었을 때 남는 영역을 말한다. 사용되지 않는 비효율적인 공간이다.
가변 분할 방식: 매 시점 프로그램의 크기에 맞게 메모리를 분할한다.(분할의 크기, 개수에 따른 동적인 분할) 물리적 메모리 크기보다 더 큰 프로그램은 적재가 불가하다.
외부 조각: 프로그램에게 할당되지 않은 메모리 영역인데, 크기가 작아서 프로그램을 올리지 못하는 메모리 영억. 사용되지 않는 비효율적인 공간이다.
가상 메모리 방식: 최근의 거의 모든 컴퓨터 시스템에서 사용한다. 물리적 프로그램보다 더 큰 프로그램의 실행을 지원한다. 모든 프로그램은 물리적 메모리와 독립적인 주소가 0부터 시작하는 자신만의 가상 메모리를 갖는다. OS는 가상 메모리의 주소를 물리적 메모리 주소로 매핑하는 기술을 이용해서 주소를 변환시켜서 프로그램을 물리적 메모리에 올린다. 따라서 실행될 수 있는 프로그램의 크기는 가상 메모리 크기에 의해 결정된다.
스왑 영역(swap area): 현재 사용되고 있는 부분만 메모리에 올리고, 나머지는 하드 디스크와 같은 보조 장치에 저장했다가 필요할 때 적재하는 방식으로 이때 사용되는 보조 기억 장치의 영역이 스왑 영역이다.
References
운영체제
[운영 체제와 정보 기술의 원리] 반효경 지음